
The term confuses some ABC users, here is a simple, short explanation to answer the Unicode font question.I have the Unicode topic briefly touched some time ago, but that not all the Unicode fonts explains, on the round earth there are of course a number of peoples, languages and character sets / fonts. To cover all the special characters there are the Unicode fonts! Here is a short list of Unicode fonts: ►... Wiki Unicode fonts Contents: 1.) ... What is a Unicode font!
|
| (Image-2) Example Unicode Fonts / Chars! |
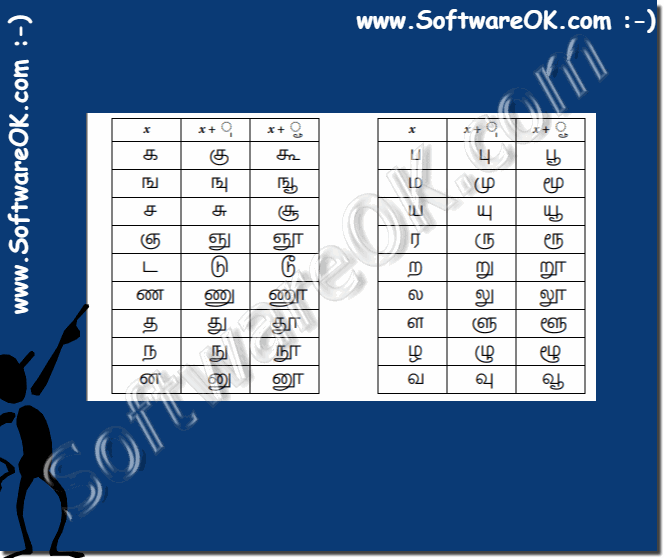 |
2.) The base Unicode mapping font is limited to 65,535!
The original Unicode specification, known as Unicode 1.0, actually only supported 65,536 (2^16) code points, which was in fact limited to 65,535 because code point 0 was not used. This number of code points was represented by using 16-bit encodings such as UTF-16.
However, Unicode has been greatly expanded since its inception. The current version, known as the Unicode Standard, supports millions of code points. The Unicode standard uses various encoding schemes such as UTF-8, UTF-16 and UTF-32 to represent this larger number of code points. UTF-8 has become particularly popular because it saves space and is compatible with ASCII.
With the introduction of the Unicode Supplementary Multilingual Plane (SMP) and later the Unicode Plan 1 to 16, a total of more than a million characters can now be represented. This allows encoding characters for almost all known languages, as well as a variety of symbols, emojis and special characters for various purposes.
3.) How many characters are possible with Unicode fonts?
Basic Latin letters (AZ, a-z)
Latin letters with accents and diacritics
Greek letters
Cyrillic letters
Arabic letters
Hebrew letters
Chinese, Japanese and Korean characters (CJK symbols)
Symbols and pictograms
Mathematical Symbols
Technical symbols
Currency symbols
Emojis
Historical characters
And many more special symbols and characters for various purposes
The number of supported characters continues to grow with each new version of Unicode. It is important to note that not all characters are available in all fonts, but Unicode defines which characters should be present and how they should be encoded to ensure consistent representation and interchangeability.
4.) Does UTF-8 support more characters than Unicode?
UTF-8 is a Unicode character encoding scheme that uses variable byte sequences to represent the different code points. It is important to understand that UTF-8 and Unicode are two different concepts:
Unicode:
Unicode is an international standard that assigns a unique number (code point) to each character, symbol, or character in all writing systems in the world. Unicode defines the characters and their encoding, but it is not an encoding itself.
UTF-8:
UTF-8 is one of the encoding schemes used by Unicode to convert the code points into a sequence of bytes that are stored and transmitted in computers can be. It is a variable length encoding scheme, meaning that it can represent the code points with different length byte sequences.
Info:
UTF-8 is designed to support the full width of Unicode code points. It can therefore represent as many characters as Unicode itself, since it is only an encoding scheme for Unicode and does not support more characters than Unicode defines. In fact , UTF-8 can encode all 1,112,064 valid code points of the Unicode standard, which includes the full range of characters and symbols supported by Unicode.
UTF-8 is designed to support the full width of Unicode code points. It can therefore represent as many characters as Unicode itself, since it is only an encoding scheme for Unicode and does not support more characters than Unicode defines. In fact , UTF-8 can encode all 1,112,064 valid code points of the Unicode standard, which includes the full range of characters and symbols supported by Unicode.
FAQ 89: Updated on: 13 March 2024 19:58